
Explore how Kubernetes, Prometheus, and Documatic work together to manage workloads, monitor performance, and streamline incident response effectively.
Introduction
Cloud-native technologies are transforming how we build and manage modern infrastructure. With distributed systems becoming more common, teams need reliable ways to deploy, monitor, and manage their applications. Orchestration ensures everything runs smoothly, infrastructure monitoring tools keep an eye on performance, and well-organized documentation helps teams resolve issues quickly.
Managing these tasks efficiently requires specialized tools. Incident management software like Kubernetes, Prometheus, and Documatic addresses these needs in complementary ways. Kubernetes orchestrates containerized applications, ensuring they run and scale properly. Prometheus provides continuous real-time incident tracking and alerting, helping detect and fix issues early. Meanwhile, Documatic ensures that documentation is easy to access, improving collaboration and supporting ITIL incident management frameworks.
These tools create a solid foundation for managing cloud-native systems and achieving SLA and KPI compliance. In this article, we’ll explore each tool’s role and how they integrate into an efficient incident management platform.
Kubernetes: Orchestrating Containerized Workloads
What is Kubernetes?
Kubernetes is an open-source platform that simplifies the management of containerized applications. It automates how applications are deployed, scaled, and managed, enabling developers to focus on building software rather than worrying about infrastructure.
With Kubernetes, containers—which are lightweight, self-contained units that include all necessary software components—are orchestrated across multiple machines. This supports incident management processes by preventing disruptions and helping applications recover quickly through automated restarts. By using MTTR improvement strategies, Kubernetes reduces downtime, ensuring that workloads remain available and resilient.
The core Kubernetes Components that form the system do include and are not limited to:
- Pods: The smallest unit in Kubernetes, representing one or more containers that share the same network and storage. Pods ensure containers can work together seamlessly within the same environment.
- Nodes: Physical or virtual machines that run the containers. Every Kubernetes cluster consists of multiple nodes, each acting as a worker in the system.
- Services: A way to expose containers to the outside world or to other containers within the cluster, ensuring smooth communication.
- Controllers: Help maintain the desired state of the system by scaling workloads or restarting containers if something goes wrong.
When applications are built as microservices, Kubernetes makes it easier to deploy, manage, and scale them dynamically. For instance, during peak retail seasons, Kubernetes can scale up essential services to handle demand. After traffic subsides, it scales them down to conserve resources, aligning with MTTR improvement strategies.
A Summary of Why Kubernetes Matters
Kubernetes brings several advantages to developers and operations teams. It automates the deployment, scaling, and ongoing management of containers, eliminating the need for manual interventions. Teams can define the desired state of the application, and Kubernetes plays a crucial role within incident management platforms, ensuring system health through continuous orchestration and proactive workload management.
Prometheus: Monitoring and Observability
What is Prometheus?
Prometheus is an open-source monitoring system designed to collect and store metrics as time-series data. It works alongside orchestration tools like Kubernetes by monitoring the health of applications, infrastructure, and systems in real time. Its reliable design ensures that incident management metrics are always available, even when disruptions occur, supporting SLA and KPI compliance.
Below are some of Prometheus’ core features that enable it to work effectively when it comes to data retrieval, alerting, and analysis.
- Pull-Based Metrics Collection: Prometheus actively pulls data from predefined targets, ensuring real-time incident tracking.
- Alerting: Prometheus triggers alerts when key metrics—like high memory or CPU usage—exceed thresholds, providing teams with actionable insights based on their incident response playbook.
- PromQL (Prometheus Query Language): A flexible query language is used to filter, aggregate, and analyze metrics stored in the time-series database. This makes it easy to generate insights and dashboards from complex datasets.
Integration with Kubernetes
Prometheus integrates seamlessly with Kubernetes, scraping metrics from various components such as pods, nodes, and services. It tracks system health indicators like memory consumption, container uptime, and network latency. This data helps teams maintain ITIL incident management standards by detecting and resolving issues early.When a container fails or exceeds resource limits (e.g., CPU > 90%), Prometheus sends a real-time alert to the DevOps team, ensuring a quick response. These alerts align with SLA response times, helping organizations maintain incident management best practices.
Monitoring container health helps identify issues before they affect the application. Prometheus collects metrics such as pod availability and cluster resource utilization, ensuring workloads are running efficiently and that there are no bottlenecks. Why is this helpful?
Alerting for Incidents
One of Prometheus’s most powerful features is real-time alerting. It allows teams to respond quickly to issues as they arise. Alerts are based on predefined thresholds or patterns observed in the metrics data.
If a container crashes or starts consuming excessive resources for example CPU utilization > 90%, Prometheus can send an alert to the DevOps team using means such as e-mail or Slack. This real-time notification helps ensure the issue is resolved before it impacts users or causes service disruptions. Whether the incident is related to resource overuse or failed deployments, these alerts make incident management faster and more effective.
Documatic: Documentation and Knowledge Management in DevOps
What is Documatic?
Documatic is an incident management tool designed to help software teams respond to issues quickly and effectively. It integrates insights from observability tools, organizes bridge calls, and maps dependencies across codebases to pinpoint the root cause of incidents faster. By reducing alert noise and providing actionable insights, Documatic ensures smoother incident handling, helping teams maintain system stability and minimize downtime.
Use in Kubernetes Environments
Managing Kubernetes workloads often involves complex interactions between microservices. When things go wrong, tracking the origin of a problem can be challenging. Documatic plays a crucial role in such environments by:
- Linking Alerts and Incidents: It correlates metrics from monitoring tools like Prometheus, grouping related incidents to reduce noise.
- Mapping Dependencies: Visualizing how code, infrastructure, and microservices interact, helping teams understand the full impact of an incident.
- Coordinating Incident Response: Teams can organize bridge calls with the right experts through Documatic to speed up troubleshooting.
By serving as incident reporting software, Documatic ensures that each incident is documented thoroughly. This enables teams to refine processes over time, improving their overall incident-handling capabilities.
How They Work Together
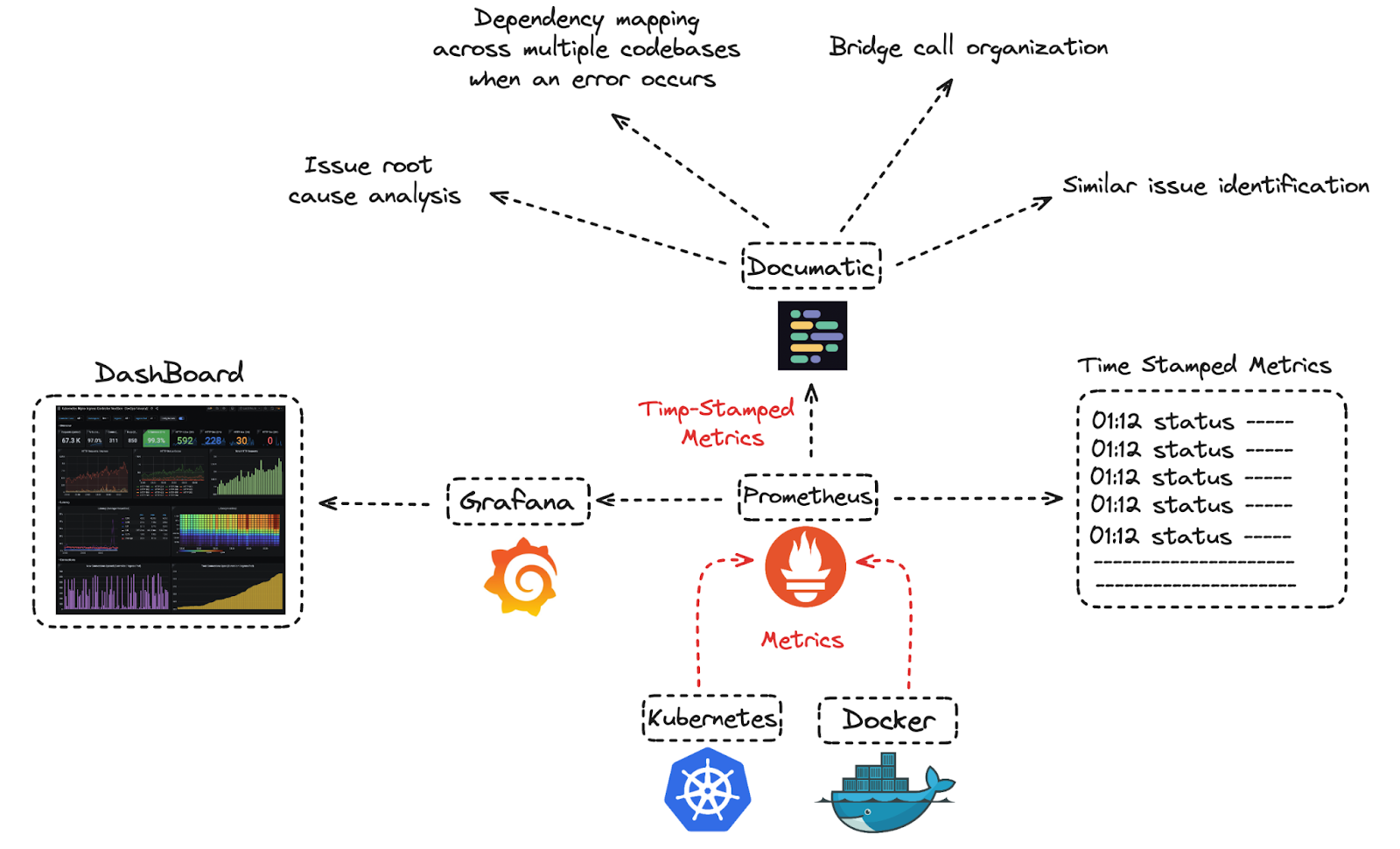
Kubernetes, Prometheus, and Documatic complement one another, creating a seamless workflow for managing modern infrastructure. Each tool addresses a specific need: Kubernetes orchestrates container workloads, Prometheus monitors performance, and Documatic ensures efficient incident management by organizing alerts and mapping dependencies.
Here’s how they interact:
- Kubernetes: Kubernetes ensures containers are running smoothly by distributing workloads across nodes and restarting failed containers as needed.
- Prometheus: Prometheus scrapes metrics from Kubernetes clusters and identifies potential issues like resource bottlenecks or service outages. Monitors infrastructure in real time and sends alerts to the DevOps team based on predefined metrics, supporting real-time incident tracking.
- Documatic:Documatic correlates alerts from Prometheus with recent code changes or infrastructure modifications. It visualizes dependencies, making it easier to pinpoint root causes and coordinate the right team members through a bridge call.
This integrated workflow shows how Kubernetes, Prometheus, and Documatic complement each other effectively. Kubernetes handles workload orchestration, ensuring services run smoothly and scale as needed. Prometheus offers proactive monitoring, identifying issues early through real-time alerts. Documatic streamlines incident resolution by correlating alerts with code changes and providing teams with the insights needed to quickly address problems. Together, these tools minimize downtime and enhance system reliability by making incident management faster and more efficient.
Benefits of Using Kubernetes, Prometheus, and Documatic Together
Bringing Kubernetes, Prometheus, and Documatic together delivers a range of operational benefits, when used together, they provide a comprehensive framework for efficient infrastructure management, monitoring, and incident response.
1. Enhanced System Resilience through Orchestration and Incident Management
Kubernetes ensures high availability by automating failover and restarting failed containers. When integrated with Prometheus, the system gains proactive capabilities—identifying potential issues through metrics monitoring. Documatic strengthens resilience further by automating root cause analysis and orchestrating the right incident response, preventing minor disruptions from becoming major outages.
2. Operational Alignment and Smoother Collaboration
These tools promote smooth workflows across operations teams. Kubernetes simplifies complex infrastructure operations, Prometheus ensures that performance insights are continuously accessible, and Documatic enhances collaboration by arranging bridge calls automatically with relevant experts. This alignment reduces operational silos, ensuring that developers, engineers, and support teams are always in sync.
3. Data-Driven Insights for Continuous Improvement
The integration of Kubernetes, Prometheus, and Documatic helps organizations adopt a data-centric approach. Prometheus provides deep insights into performance trends over time, while Documatic identifies recurring patterns and correlates them with historical issues. These insights inform long-term improvements, such as refining Kubernetes configurations or streamlining DevOps processes to to align with incident management best practices and improve over time.
4. Minimized Downtime with Seamless Alert and Resolution Pipelines
Prometheus tracks performance metrics and triggers alerts in real time. Documatic enhances this by correlating alerts with code changes and infrastructure adjustments, ensuring fast, well-informed responses. With Kubernetes handling workload recovery and Documatic streamlining team coordination, the risk of extended downtime is minimized, protecting user experience and service availability.
Conclusion
Orchestration, monitoring, and documentation are essential for managing modern systems. Without them, teams would struggle to keep services running, detect issues quickly, and respond effectively according to ITIL incident management practices.
Kubernetes, Prometheus, and Documatic work well together to streamline incident management processes within DevOps workflows. Kubernetes handles workload management and aligns with MTTR improvement strategies by scaling services dynamically and restarting failed containers automatically. Prometheus continuously monitors performance, providing real-time incident tracking and alerting teams to potential problems. Documatic offers incident reporting software and ensures easy access to up-to-date documentation for troubleshooting and automated root cause analysis. Using them together improves efficiency, promotes collaboration, and helps meet SLA and KPI targets.
As hybrid and multi-cloud setups become more common, these tools will continue to grow in importance. Kubernetes will manage workloads across different environments, while Prometheus’ incident management metrics will help monitor more complex systems. Documatic will keep teams aligned through documentation and adherence to incident management best practices. Staying ahead with these tools ensures organizations remain prepared for future challenges, reduce downtime, and maintain operational efficiency within an AI-powered incident management platform.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments