
Learn how to handle high-pressure software incidents with real-world examples, practical strategies, and AI-driven tools for faster resolution and prevention.
Introduction
In software development, high-pressure incidents are inevitable. Whether it's a production server crashing or a security breach exposing sensitive data, these moments demand swift action and clear thinking. Teams must be ready to handle unexpected challenges while keeping downtime minimal and users informed. How your team responds in these situations can be the difference between a quick recovery and long-lasting damage to both reputation and operations.
This article explores real-world examples of incident management and the key lessons they provide—from cross-functional collaboration to using AI tools for smarter detection. We’ll also cover best practices like running incident simulations and post-mortem reviews to ensure that each incident becomes a stepping stone toward building a more resilient development process.
What Constitutes a High-Pressure Incident?
Think of a high-pressure incident in software development like a fire alarm going off in the middle of a party—everyone scrambles to fix the problem, and time is of the essence. These incidents demand swift action, and often the stakes are high, involving frustrated customers, crashing systems, or looming deadlines.
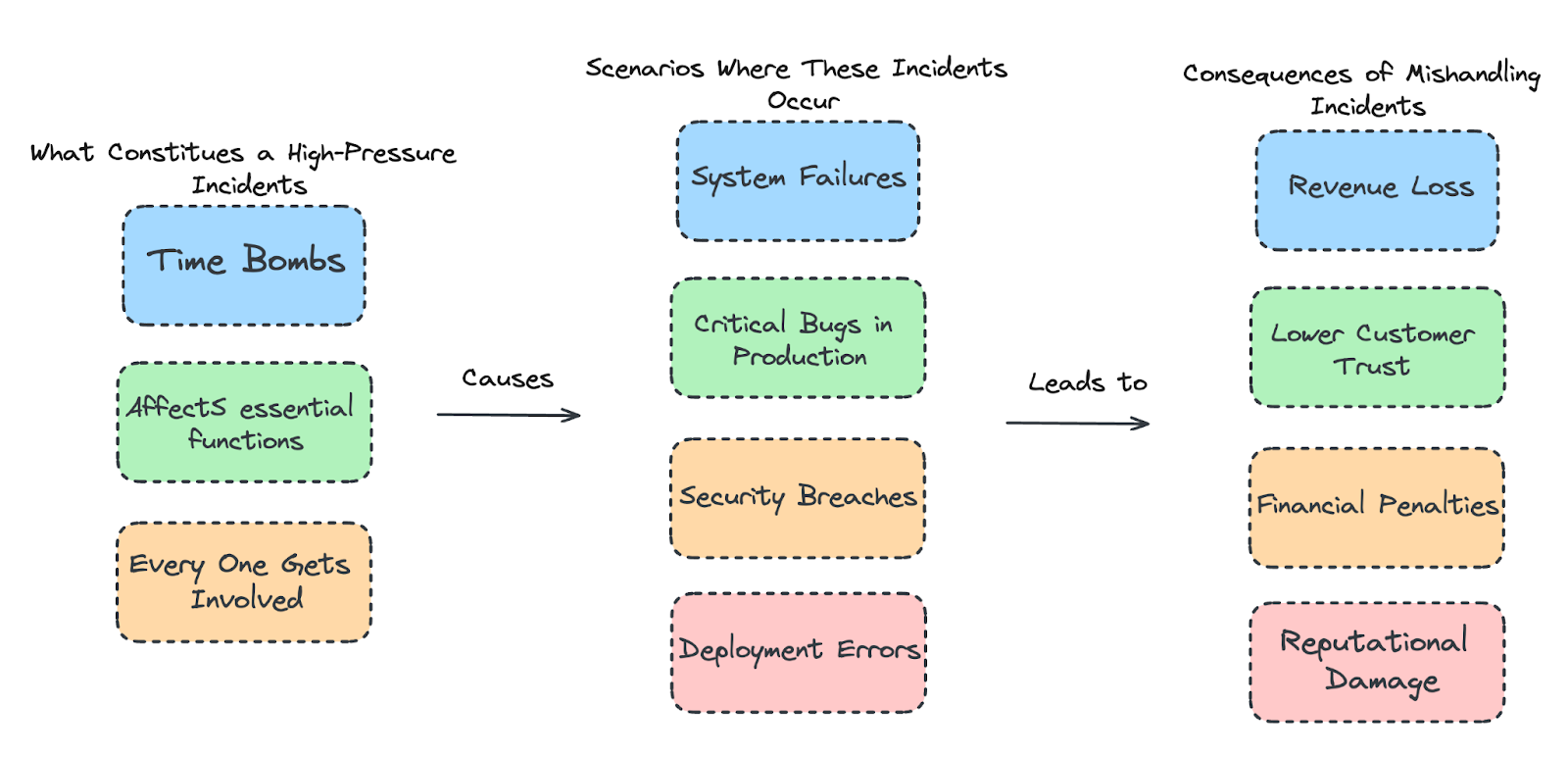
Definition and Characteristics of High-Pressure Incidents
- They’re time bombs: You don’t have the luxury of time. These issues need to be tackled right now before things spiral out of control.
- They affect essential functions: It’s not just a cosmetic bug. These incidents disrupt critical services, such as crashing websites or locking customers out of their accounts.
- Everyone gets involved: It’s an all-hands-on-deck situation. Developers, DevOps, and even customer service teams need to collaborate, often under pressure, to resolve the issue.
Common Scenarios Where These Incidents Occur
- System Failures: Imagine your app goes down on Black Friday! Servers crash, databases get overloaded, and suddenly, no one can shop.
- Critical Bugs in Production: You just deployed an update, and now users can’t log in or complete purchases.
- Security Breaches: A hacker finds a way into your system, potentially exposing customer data. Every second counts in minimizing the fallout.
- Deployment Errors: The code works perfectly in staging, but something breaks the moment it goes live. Now the team is rushing to roll back before users notice.
Potential Consequences of Mishandling Incidents
- Downtime = Revenue Loss: For every minute your service is down, you’re losing potential sales or users.
- Customer Trust Takes a Hit: If users feel frustrated or insecure, they might not come back. Trust is hard to rebuild once it’s lost.
- Financial Penalties: Breaches and outages often come with fines or regulatory action, depending on the industry.
- Reputational Damage: A messy response can leave a permanent mark on your brand’s reputation. Think of it as a bad Yelp review but on a much bigger scale.
At the end of the day, managing these incidents effectively isn’t just about having technical skills—it’s about keeping calm under pressure, communicating clearly, and learning from each situation to avoid future disasters.
Real-Life Scenario 1: Google Assistant Bug—Escalation Delays Lead to Extended Service Issues
The incident revolves around Google Home, a smart speaker powered by Google Assistant, which responds to voice commands such as “OK Google.” To put it simply, the user interacts with Google Home using a hot word that triggers the assistant, with the device storing speaker recognition files on the server. Google Assistant’s server implements a quota policy to prevent overload during peak usage with the system being designed to handle occasional bursts of traffic, but in this specific case, a software bug caused the requests to skyrocket.
A Brief Incident OverviewDuring the rollout of Google Assistant version 1.88, the team discovered that the devices were sending requests for speaker recognition files 50 times more frequently than usual. Instead of the expected once-a-day request, devices began pinging the server every 30 minutes. This increased load led to users experiencing degraded service, with Google Home devices occasionally failing to respond to commands. Initially, the rollout was paused at 25% deployment to investigate the issue.
Developers identified a related bug, which caused the assistant to restart every time the device refreshed its authentication state. They mistakenly linked the excess traffic to this known issue and resumed the rollout. By May 31, the new version was running on 50% of Google Home devices. However, customers soon reported that commands were triggering error messages instead of responses.
What Were the Challenges faced and their Response?The root cause wasn’t apparent at first. Miscommunication between server and client developers slowed down the debugging process. Both sides assumed the issue was resolved after temporarily increasing the quota limit, but the real bug persisted. On June 3, the rollout hit 100%, and the situation escalated as users encountered more frequent failures. Frustrated customers flooded support channels, including social media, with complaints.
Adding to the challenge, the rollout was completed over a weekend, limiting the availability of key developers to respond quickly. Teams scrambled to manage the crisis remotely, requesting additional quota increases to stabilize the system. Despite these efforts, the issue wasn’t declared as a formal incident, which could have facilitated quicker coordination among teams and more efficient resolution.
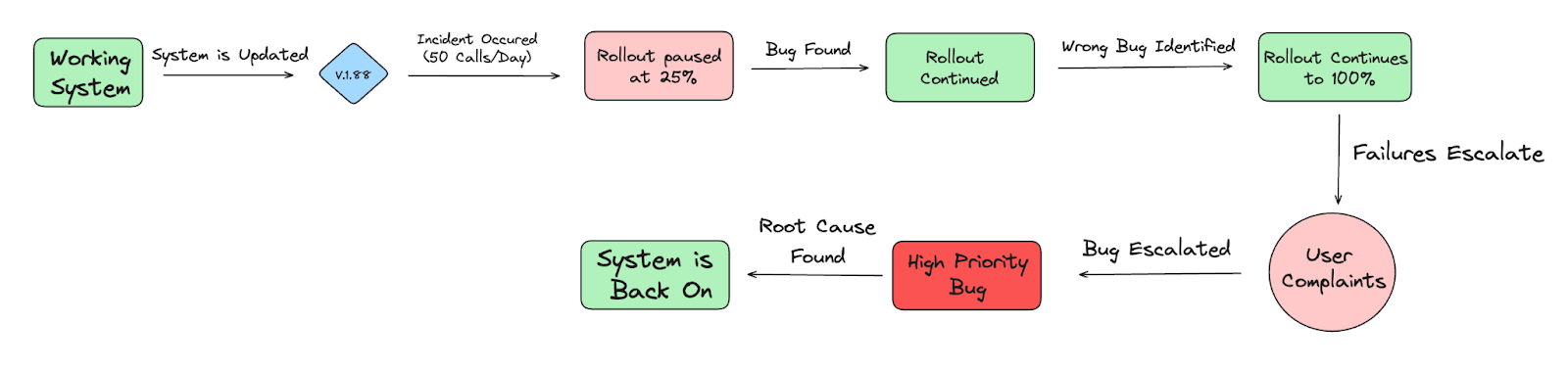
Key Takeaways and Lessons Learned after the IncidentOn June 4, after days of troubleshooting, the support team finally escalated the bug to the highest priority. With better communication and centralized troubleshooting efforts, engineers identified the root cause: the buggy code in version 1.88 was fetching data far too frequently, overwhelming the servers. Adjusting the quota and fixing the code restored service, and users began receiving normal responses.
This incident highlighted several lessons:
- Proactive Escalation: Declaring an incident early helps coordinate teams and prevent further disruptions.
- Careful Rollouts: Deploying critical updates during business hours ensures that developers are available to respond.
- Accurate Troubleshooting: Miscommunication between teams can lead to delays. Centralized tracking and clear communication are crucial during incident handling.
Source: Google SRE
Real-Life Scenario 2: Ericsson Certificate Expiry Outage
In December 2018, Ericsson, a global leader in telecommunications, encountered a critical incident when a digital certificate used for its SGSN-MME software expired unexpectedly. The SGSN-MME component plays a crucial role in managing mobile networks by handling data traffic and mobility. The sudden certificate expiry disrupted mobile services for multiple carriers, including O2, GiffGaff, and Lyca Mobile, affecting millions of users.
A Brief Incident OverviewThe incident struck on December 6, 2018, when users across the UK and 11 other countries, including Japan, experienced widespread outages. Around 32 million mobile users in the UK lost access to essential services like 4G connectivity and SMS messaging. The expired certificate disabled the SGSN-MME software, leaving mobile networks unable to manage traffic effectively. As a result, customers found themselves without basic communication services, causing frustration and disruptions for individuals and businesses alike.
What Were the Challenges faced and their Response?Ericsson’s engineering teams worked swiftly to address the problem. By the end of December 6, the company managed to restore services for the majority of affected users. Ericsson also announced that the faulty software versions were being decommissioned to prevent future incidents.
However, the outage exposed a vulnerability in managing critical systems. Digital certificates, which are essential for secure communication, need to be renewed regularly. In this case, the certificate oversight disrupted services at a large scale. Furthermore, such lapses not only cause downtime but also expose systems to potential cyberattacks, as expired certificates can leave networks temporarily unprotected from malicious activity.
Key Takeaways and Lessons Learned after the Incident
- Proactive Certificate Management: Regular monitoring and automated alerts are essential to ensure the timely renewal of digital certificates.
- Redundancy in Systems: Backup systems could mitigate disruptions if certificates expire unexpectedly.
- Effective Communication: Clear communication with customers is necessary to manage expectations and minimize dissatisfaction during outages.
Source: Machine Identity Management
Key Lessons from Major Incident Responses in Software Development
Managing high-pressure incidents isn’t just about fixing issues—it’s about having the right processes in place to minimize impact and learn from every experience. With clear communication, smooth cross-team collaboration, and proactive drills, teams can stay prepared. Continuous documentation and fast decision-making ensure incidents become opportunities for growth, not setbacks.
Prioritize Communication
When things go south during an incident, communication is your lifeline. Internally, teams often rely on tools like Slack or dedicated incident rooms (both physical and virtual) to stay in sync. The goal is to have everyone on the same page—no unnecessary back-and-forths or missed updates. Externally, users need to be kept in the loop too. Whether through status pages, social media, or email updates, clear and timely communication reassures users and reduces panic.
Cross-Functional Team Collaboration
Major incidents are rarely confined to a single team. Development, operations, and security all need to work together seamlessly. Collaboration helps teams solve problems faster—like Google’s incident where server and client-side developers needed to align quickly to restore Google Home services. Integrated response frameworks ensure no team is left out of the loop, avoiding the delays that can result from silos.
Incident Simulations and Drills
Simulations—like chaos engineering—are a way of stress-testing your system before real issues occur. Companies like Netflix use chaos engineering to simulate service failures regularly, helping their teams prepare for unexpected outages. These drills expose weaknesses in processes or systems and give the team valuable practice. The result? When something goes wrong for real, the response feels like second nature.
Quick Decision-Making and Delegation
In high-pressure situations, waiting too long to act can make things worse. Whether it’s pausing a buggy deployment or prioritizing critical fixes, decisions need to be made quickly. Leaders must also know how to delegate. For example, Google’s incident response could have been smoother if they’d escalated the issue sooner and divided tasks more effectively across their on-call and development teams. Delegation ensures that no one person becomes a bottleneck while keeping overall control in the hands of the incident commander.
Documentation and Continuous Improvement
The work isn’t over when the incident ends—this is where post-mortem analysis comes in. The best teams treat incidents as learning opportunities, documenting what went wrong, what went well, and what needs improvement. These insights become part of the development lifecycle, helping teams fine-tune processes and avoid repeat incidents. Google’s SRE teams, for example, rely heavily on post-mortem reports to prevent recurring failures. Documentation ensures that even if personnel change, the knowledge gained from previous incidents remains accessible and useful.
Common Pitfalls to Avoid in Software Development Incident Management
Even the most experienced teams can stumble if key aspects of incident management are overlooked. Here are common mistakes that can turn a manageable issue into a prolonged disaster—and how to avoid them.
1. Lack of Preparation and Underestimating Risks
Skipping important steps like automated tests or failing to establish rollback plans leaves your team vulnerable when things go wrong. Without preparation, even minor bugs can spiral into major incidents. For example, deploying changes without testing can introduce hidden issues that disrupt services unexpectedly. Similarly, not having a rollback strategy—a way to quickly revert changes—can prolong outages and frustrate users. Teams that assume, “Nothing will go wrong” are often caught off guard when incidents strike.
2. Failure to Communicate Effectively During the Incident
In the heat of an incident, poor communication can make a bad situation worse. When key stakeholders, including customers and internal teams, are left in the dark, confusion and mistrust grow. Using disjointed communication tools or unclear messaging delays response times and leads to misunderstandings. Effective incident management requires clear, coordinated communication across teams and proactive updates to users to manage expectations. Google’s incident with their Google Home service is a perfect example—had they escalated communication earlier, they could have resolved the problem faster.
3. Not Learning from Past Failures or Breaches
Ignoring lessons from previous software incidents is a recipe for recurring problems. Post-mortem reviews are critical to identifying what went wrong and implementing preventive measures. When companies skip this step, they miss the opportunity to improve processes and systems, increasing the likelihood of repeat failures. Ericsson’s failure to manage expiring certificates properly led to a widespread outage affecting millions—something that better monitoring and documentation could have prevented.
How to Apply These Lessons to Your Software Development Team
Handling incidents well is about more than just fixing problems—it’s about being ready for the next challenge. Teams should have the right tools, communication plans, and drills in place to stay prepared. AI can help by spotting issues early, while post-mortem reviews ensure the team learns from every incident, so the same mistakes don’t happen again. With the right habits, your team can handle future challenges smoothly and efficiently.
1. Perform Incident Response Training
- Decide on a Proper Communication Channel: Ensure your team knows where to communicate during incidents—whether it’s through Slack, dedicated incident rooms, or specialized tools. This minimizes confusion and speeds up collaboration.
- Prepare a List of Specialized Contacts: Have an updated contact list of key personnel, including DevOps, security experts, and product managers. This ensures the right people are involved without delays.
- Perform Proper Incident Categorization: Not every issue requires the same level of urgency. Categorizing incidents by severity helps allocate resources effectively. Critical incidents, like outages or security breaches, require immediate response, while low-priority issues can be managed without disrupting other tasks.
- Conduct Incident Response Drills: Regular drills, including simulations like chaos engineering, help prepare your team to handle real incidents smoothly. Companies such as Netflix run chaos experiments to identify weak points in their systems and ensure their teams are always ready to act under pressure.
2. Utilize AI in Incident Management
- Easier Root Cause Detection with AI: AI-powered tools like Documatic can analyze logs and monitor systems to detect patterns, speeding up the process of finding the root cause. This reduces downtime and ensures your team focuses on solutions, not just diagnostics.
- Preventing Repetitive Incidents: AI helps identify recurring issues and suggests preventive measures based on historical data. Automated learning systems make it easier to avoid similar failures in the future.
- Organizing the Incident Management Process: AI tools streamline workflows by automating alerts, ticket creation, and escalations. This ensures every step of incident management—from detection to resolution—is smooth and well-documented.
3. Minimize the Chance of New Issues
- Do Proper Checks: Incorporate automated testing and code reviews into your development cycle to catch issues early. Ensure that every deployment has a rollback plan, so you can reverse changes if needed.
- Use AI for Future Incident Detection: Predictive analytics powered by AI and machine learning can analyze trends and alert teams to potential risks before they escalate into major incidents. This proactive approach helps maintain system health and stability.
4. Log and Learn from Repetitive Incidents
- Perform Post-Mortem Reviews: After resolving an incident, conduct a post-mortem to document what went wrong and what worked. This analysis feeds directly into future improvements. Successful organizations treat post-mortems as essential for continuous improvement and use them to refine their incident response processes over time.
Conclusion
Handling high-pressure incidents in software development is like running a fire drill—you need preparation, clear communication, and the ability to stay calm under pressure. It’s not just about solving the immediate issue but also about learning from it to build stronger systems and processes. By training your team, using AI tools to catch problems early, and running post-mortem reviews, you set your team up for smoother resolutions in the future.
These incidents are bound to happen, but the key lies in how you respond. With the right strategy—quick decision-making, seamless collaboration, and proactive measures—your team can not only handle crises but also emerge stronger and more prepared. Think of each incident as a learning opportunity, and soon, handling high-stakes situations will feel like second nature.
Ready to take your incident management to the next level? Streamline your process, detect root causes faster, and prevent repetitive issues with AI-powered tools. Try Documatic today and experience how automated insights and smooth workflows can transform your team’s response to high-pressure incidents.
👉 Sign up now for Documatic’s free trial and keep your systems running smoothly, no matter what challenges come your way!
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments