
Redis is a widely-used in-memory data store that is known for its speed and flexibility, making it ideal for building high-performance applications. However, with its increasing popularity and the explosion of high-traffic applications, it becomes crucial to optimize Redis to keep up with the growing data demand. In this blog post, we will explore the best practices and techniques for tuning Redis performance to ensure your application can handle the most demanding workloads. So, whether you're a seasoned Redis user or just getting started, read on to learn how to optimize your Redis database for lightning-fast speed and excellent scalability.
Table of Contents
- How Redis Works?
- How to optimize your Redis application?
- Use Redis data types wisely
- Use pipelining
- Use Redis cluster
- Use a connection pool
- Use Redis Sentinel
- Use Redis TTL to expire keys
- Why you should perform these optimizations?
- Why do developers fall under the non-optimized path?
How Redis Works?
Before we dive into how to optimize your Redis application lets quickly understand how Redis works.
Redis works as an in-memory data store, which means it stores data in RAM instead of on a hard drive. This makes Redis extremely fast, in fact, Redis can read and write data to and from memory in micro- or even nanoseconds.
When you add data to Redis, it first stores the data in memory, and then optionally writes it out to disk, depending on your configuration. This is a key feature that allows Redis to be so fast - if the data is already in memory, Redis doesn't need to go through the slower process of reading it from a hard drive.
Redis is often used as a caching system, where it stores frequently accessed data in memory so that it can be served faster. For example, if a web application needs to access a database to retrieve data for every request, that can be slow, even with a fast database. By using Redis as a cache, the web application can check Redis first, and if the data is there, it can be served back to the user without ever needing to hit the database.
Redis also supports many types of data structures, including strings, hashes, lists, sets, and sorted sets. These data structures allow for sophisticated data storage and retrieval. For example, a Redis hash can represent an object and the keys within the hash can represent attributes of that object.
In addition, Redis provides advanced features like pub/sub messaging, which allows for real-time messaging between clients, and transactions, which allow multiple Redis commands to be executed as a transaction.
How to optimize your Redis application?
Optimizing Redis applications can significantly improve the performance of your web application, and provide a better experience to your users. Here are some tips for optimizing Redis applications:
Use Redis data types wisely
Redis provides five data types: strings, hashes, lists, sets, and sorted sets. Each of them is designed for specific use cases, so choose one based on the nature of your data. For instance, if you need to store key-value pairs, use hashes, if your data is ordered, use sorted sets. Using the right data type can improve your application's performance significantly.
Use pipelining
Redis provides pipelining, which is a way of sending multiple commands to Redis without waiting for the response of each command before sending the next one. This can significantly reduce the round-trip time and improve the performance of your application.
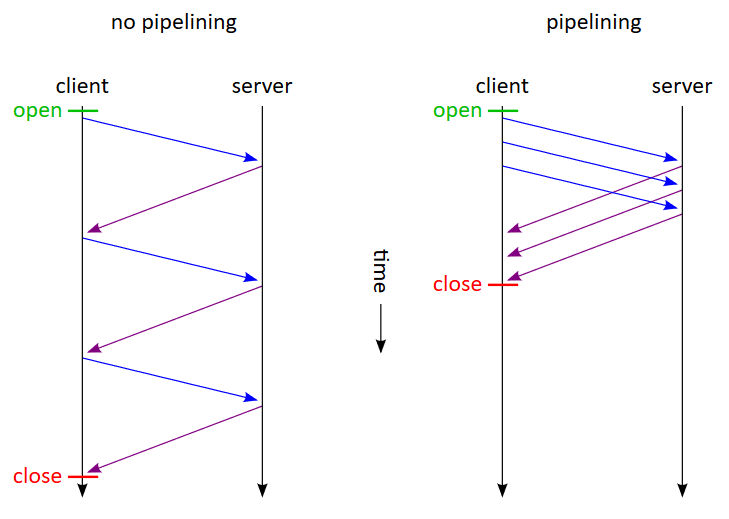
Here is an example of how you can use pipelining in Node.js:
const redis = require('redis');
const client = redis.createClient();
client.pipeline()
.set('key1', 'value1')
.set('key2', 'value2')
.exec((err, results) => {
console.log(results);
});
In the example above, we are using the pipeline() function of the redis client to send multiple set() commands to Redis in a single call.
Use Redis cluster
By Redis Cluster, you can scale Redis horizontally across multiple nodes. It can improve the performance of your application by distributing the load among multiple nodes.
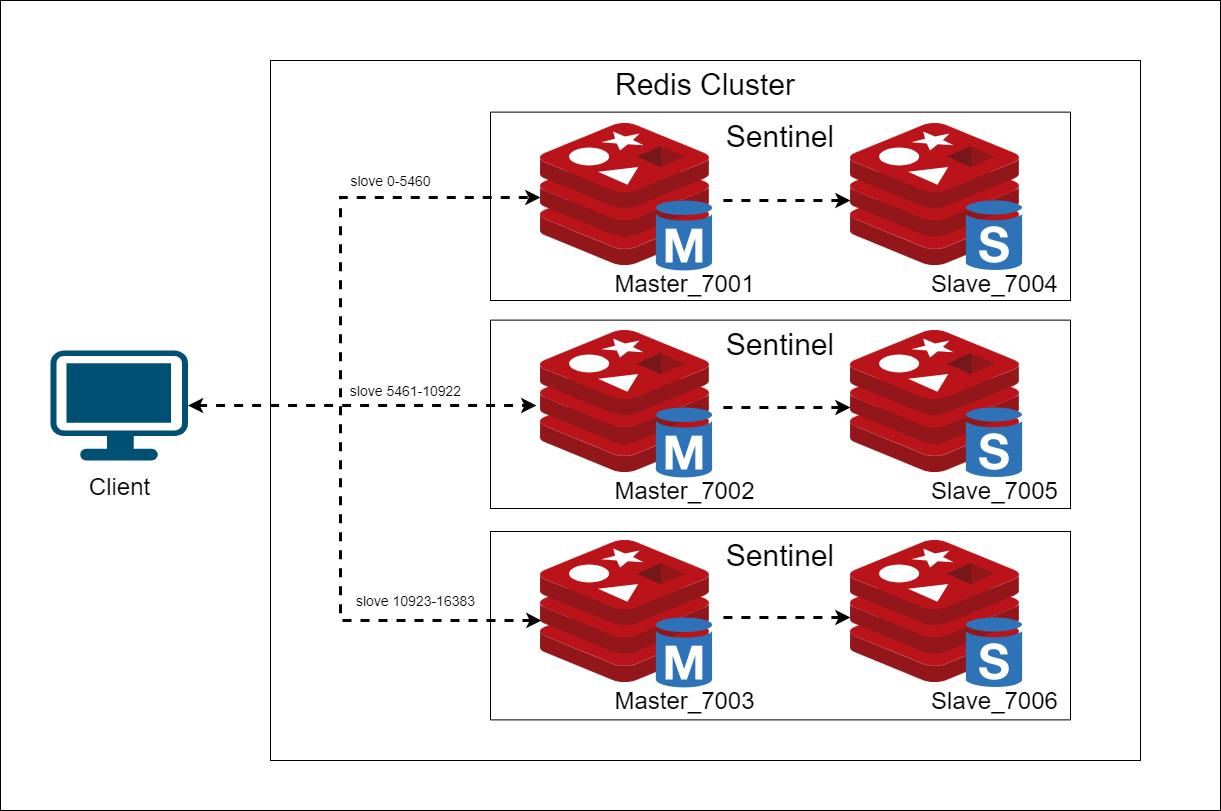
Here's an example of how you can use Redis Cluster in the redis client for Node.js:
const Redis = require('ioredis');
const redisNodes = [
{
host: '127.0.0.1',
port: 7000,
},
{
host: '127.0.0.1',
port: 7001,
},
{
host: '127.0.0.1',
port: 7002,
}
];
const redis = new Redis.Cluster(redisNodes);
redis.set('mykey', 'Hello Documatic!')
.then(() => redis.get('mykey'))
.then(result => console.log(result));
Use a connection pool
Creating a new connection to Redis for every request can be expensive. Instead, you should use a connection pool, which will manage a set of reusable connections to Redis.

Here's an example of how you can use a connection pool:
const redis = require('redis');
const { createPool } = require('redis-pool');
const pool = createPool({
create: () => redis.createClient(),
destroy: client => client.quit()
});
pool.acquire().then(client => {
client.set('key', 'value', () => {
pool.release(client);
});
});
Use Redis Sentinel
Redis Sentinel is a high-availability solution for Redis that allows you to monitor your Redis instances and perform automatic failover in case of a node failure. Using Redis Sentinel can help ensure that your application is always available and minimize downtime.
Here's an example of how to use Redis Sentinel in Node.js:
const Redis = require("ioredis");
const sentinels = [
{ host: "127.0.0.1", port: 26379 },
{ host: "127.0.0.1", port: 26380 },
{ host: "127.0.0.1", port: 26381 },
];
const redis = new Redis({
sentinels: sentinels,
name: "Documatic",
});
redis.set("org", "documatic");
redis.get("org", (err, result) => {
console.log(result);
// output: docmatic
});
Use Redis TTL to expire keys
Redis allows you to set a time-to-live (TTL) for keys, which specifies how long a key should exist before it is automatically removed. This can be useful for caching data that is only relevant for a certain amount of time, or for limiting the amount of data stored in Redis.
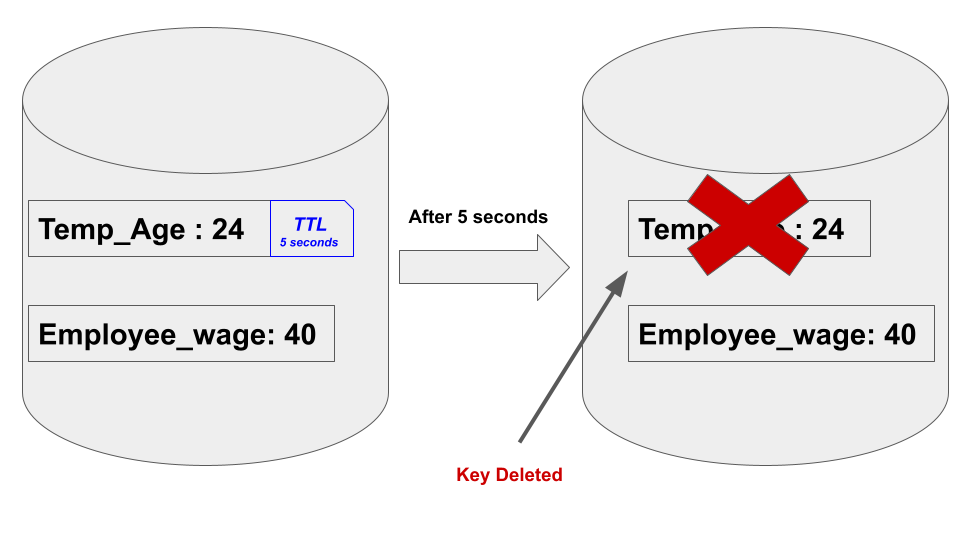
const redis = require('ioredis');
// Create a Redis client
const client = redis.createClient();
// Set a key with a TTL of 60 seconds
client.set('org', 'Documatic', 'EX', 60);
// Retrieve the value of the key
client.get('org', (err, value) => {
console.log(value); // Output: Documatic
});
// Wait for the key to expire
setTimeout(() => {
client.get('og', (err, value) => {
console.log(value); // Output: null
});
}, 60000);
Why you should perform these optimizations?
Performing optimizations helps improve the performance of Redis in high-traffic applications. In general, high-traffic applications typically have a large user base and generate a high volume of requests, which can put a lot of strain on the Redis server. This can lead to performance problems such as slow response times, high latency, and system instability.
By performing optimizations, developers can improve Redis' performance by reducing latency, improving response times, lowering memory usage, and reducing server load. These optimizations ensure that Redis can maintain high-performance levels, even during peak usage or periods of high traffic.
In addition, optimized Redis instances can also help organizations reduce server costs by minimizing the number of servers required to handle the same amount of traffic. By improving Redis' responsiveness, organizations can handle larger traffic volumes with fewer servers, which results in cost savings.
Why do developers fall under the non-optimized path?
There are several reasons why developers may struggle with optimizing code. Here are some of the most common issues:
Lack of Knowledge and Experience
One of the main reasons why developers may fall under the non-optimized path is due to a lack of adequate knowledge or experience with performance optimization techniques. This can lead to suboptimal code that may not perform as well as it could.
For instance, using a linear search instead of a binary search algorithm for large datasets can result in significant performance issues.
Time Pressures
Dev teams are often under pressure to deliver code quickly, which can lead to optimization taking a back seat. The focus is more on getting the code out the door, rather than ensuring that it is fully optimized.
Lack of Resources
Suppose you are developing software for a client who cannot provide you with the necessary hardware or infrastructure to optimize the code's performance. In that case, you may have no other choice than to deliver suboptimal code since your options for optimization are limited.
Incomplete Requirements
If performance requirements are not clear or incomplete, this can lead to the dev team not being able to fully optimize the code. Without clear requirements, it can be difficult to know what optimizations are needed.
Prioritizing Features Over Optimization
Sometimes, dev teams may prioritize implementing new features over optimizing existing code. While this may be necessary for business goals, it can lead to suboptimal code that can cause performance issues.
Suppose the company you work for is launching a new product, and the priority is to launch it quickly with all the necessary features instead of taking a bit more time to optimize it. In that case, developers may not have the time to spend optimizing the code.
Unintentional Impact
Making changes to an application without considering the impact on performance can also lead to suboptimal code. This is especially true for large-scale changes that impact the overall architecture of an application.
Suppose a developer changes a crucial section of code without understanding how it could impact performance. In that case, it is possible that the code's performance may degrade.
Lack of Adequate Testing
Without adequate testing, it can be difficult to analyze the impact of code changes on performance. This can result in performance issues that may go unnoticed until much later on.
Sometimes I also write unoptimized code for various reasons that I mentioned above. But as we all know it's a bad practice. So, It's better if you optimize your code so it won't affect your application's performance in any way.
Wrapping up
Redis is a highly performant and scalable in-memory database that can be a great choice for high-traffic applications. However, to achieve maximum performance, it's important to properly tune Redis and optimize it for your use case.
In this article, we have covered some of the most effective techniques to optimize Redis performance. By implementing these techniques, you can significantly improve the performance and scalability of your Redis database.
If you want more explanation on these or another topic just let me know in the comments section. And don't forget to ❤️ the article. I'll see you in the next one. In meantime you can follow me here:
{% user j471n %}

Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments