
What is Incident Response?
Understanding the incident lifecycle is crucial for effectively managing and resolving incidents from their onset through acknowledgment and resolution.
Introduction to Incident Response
Incident response is a critical component of an organization’s overall risk management strategy. It involves a series of well-coordinated actions aimed at identifying, containing, eradicating, and recovering from security incidents. The primary goal of incident response is to minimize the impact of these incidents on an organization’s operations, assets, and reputation. By having a robust incident response process in place, organizations can quickly address security breaches, mitigate damage, and prevent similar incidents in the future.
Definition of Incident Response
Incident response is the process of managing and responding to security incidents that compromise the security of an organization’s assets, data, or systems. This process involves several key steps:
- Identification: Detecting and recognizing an incident.
- Containment: Limiting the spread and impact of the incident.
- Eradication: Removing the root cause of the incident.
- Recovery: Restoring normal operations and services.
- Post-Incident Activities: Conducting a thorough analysis to learn from the incident and improve future responses.
By following these steps, organizations can effectively manage incidents and reduce their overall impact.
Why Incident Response Matters for Developers 🛠️💻
Incident response processes are all about having a game plan when things go wrong—whether it’s a cyberattack, a service outage, or any unexpected system failure. It’s a structured process that helps teams quickly identify, contain, and fix the issue before it spirals out of control. The ultimate goal? Get things back to normal fast and gather insights to prevent the same problem from happening again.
Incident Response Vs. Incident Management ⚔️
While incident response is the go-to action plan for handling issues in real time, incident management takes a broader approach. It’s the big picture—preparing, responding, and learning from incidents to better handle whatever comes next. Think of incident response as firefighting, and incident management as fire prevention.
An effective incident management solution can streamline the entire process, from preparation to resolution, ensuring that teams are well-equipped to handle any incident.
For this blog, we’ll walk through key strategies for creating a proactive incident response plan, step-by-step actions to take when incidents occur, and how using tools like Documatic can streamline the entire process to help teams respond faster and more efficiently.
The 6 Core Steps of an Incident Response Plan

Understanding the key features of each step can significantly enhance the effectiveness of your incident response process.
Step 1: Preparation 📝
Preparation is crucial for any incident response. In this case, the development team has already created an incident response plan that outlines roles, communication protocols, and the tools to be used. Utilizing the best incident management tools can ensure that your team is well-prepared to handle any security breach. Regular security training sessions have been held, and the team is well-versed in using monitoring tools to detect potential threats. Their response plan includes guidelines for common security breaches, like DDoS attacks or data theft, and they run regular drills to ensure everyone knows their role.
Step 2: Identification 🔍
Considered one of the most critical steps in the incident response process, the identification step relies on the team’s incident management tool to detect unusual activity. For example, a spike in traffic to the login page or multiple failed login attempts from suspicious IP addresses could indicate a problem. Using tools like Cloudflare for DDoS protection and Datadog for server health monitoring, the team can confirm that the web application is under a brute-force attack.
Step 3: Containment 🚪
At this point, the team moves to contain the incident. They implement short-term containment by blocking the malicious IP addresses and increasing the threshold for failed login attempts, preventing further damage. Effective containment strategies are crucial for managing major incidents and preventing them from escalating. For long-term containment, they plan to add two-factor authentication (2FA) as an extra security layer to the login process. Containment prevents the attack from escalating while they investigate further.
Step 4: Eradication 🛠️
With the situation under control, the team now focuses on eradicating the threat. They review the logs to ensure that no unauthorized access was gained and no malicious code was injected. After thorough checks, they apply security patches to fix any vulnerabilities that might have been exploited during the attack. They also remove any malicious scripts that could have been planted.
Step 5: Recovery 🖥️
Next, the team works on getting the application back to normal operations. To ensure that the system is stable, they roll out the updates and monitor the application closely for any signs of recurring issues. If necessary, they initiate a rollback to the last known stable version of the application. This process includes restoring any corrupted or compromised data from backups.
Step 6: Lessons Learned 📚
After the situation is fully resolved, the team conducts a post-incident review. They go over what worked, what didn’t, and how they can improve in the future. They update their incident response plan to include the new containment strategies and improve their monitoring for similar attacks. The team also starts using incident reporting tools if they already weren’t in order to document the breach and share insights with other teams, ensuring the lessons learned are put into practice.
Key Tools for Effective Incident Response
Automation Tools in Incident Response
Automation is a game-changer in incident response, reducing manual effort and speeding up resolution. For instance, monitoring tools can automatically trigger alerts when specific thresholds are breached, like an unusual spike in server load. Tools like Prometheus and Datadog can automatically scale servers to handle higher traffic during an incident, ensuring your system doesn’t crash due to resource overload.
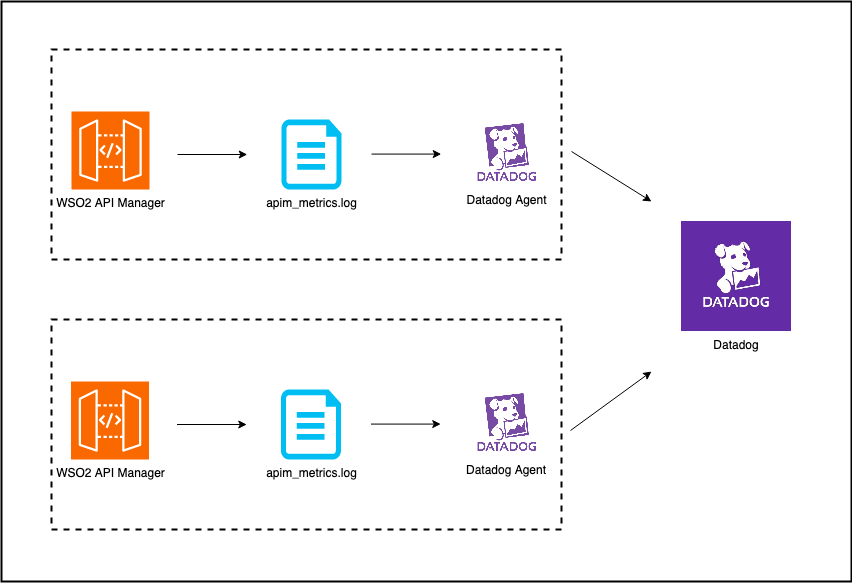
This practice of auto-scaling not only mitigates the impact of incidents but also helps contain problems before they spiral out of control. Additionally, automated response systems can quarantine affected areas of your system, further limiting damage while human teams take over.
Collaboration Tools for Incident Response Teams
Quick communication between team members is essential during an incident. Collaboration tools like Slack and Microsoft Teams integrate seamlessly with incident management platforms, enabling in-the-moment updates and rapid decision-making. These tools allow teams to create dedicated channels or threads for specific incidents, ensuring that information doesn’t get lost. Integrations with tools like Documatic mean that notifications about incidents can automatically be routed to the right team members, making the entire process more efficient.
Incident Management Software
When an incident strikes, keeping everything organized is crucial. An incident management system helps developers track, manage, and resolve incidents effectively. These tools are commonly used to automate alerts, assign tasks, and maintain a clear incident response timeline.
For instance, platforms like Documatic can also integrate with monitoring tools like Datadog and Prometheus to receive real-time data, analyze it using AI, and notify developers immediately when an issue arises. This ensures that critical issues are detected and addressed promptly, streamlining the entire incident response process and optimizing resource allocation for swift resolution.
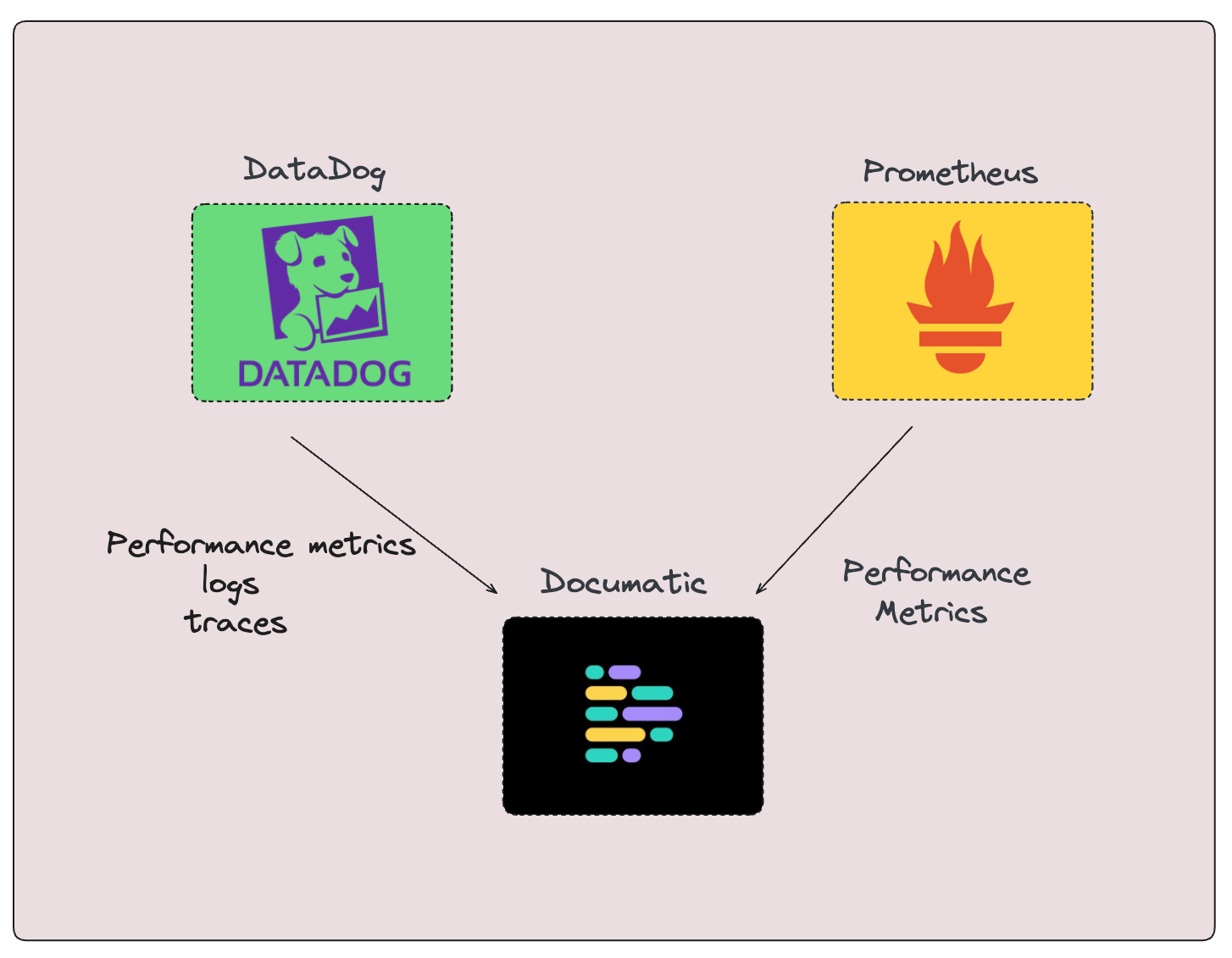
Benefits of Incident Management
Effective incident management brings numerous benefits to an organization, ensuring that incidents are handled efficiently and with minimal disruption. Here are some of the key advantages:
- Reduced Downtime and Improved System Availability: Quick and efficient incident resolution minimizes downtime, keeping systems operational and available.
- Minimized Impact on Business Operations and Revenue: By swiftly addressing incidents, organizations can prevent significant disruptions to their operations and protect their revenue streams.
- Improved Incident Response Times and Resolution Rates: A well-structured incident management process ensures that incidents are resolved faster, reducing the time taken to restore normal operations.
- Enhanced Security Posture and Reduced Risk of Future Incidents: Proactive incident management helps identify and address vulnerabilities, strengthening the organization’s overall security.
- Improved Compliance with Regulatory Requirements and Industry Standards: Effective incident management ensures that organizations meet regulatory and industry standards, avoiding potential fines and penalties.
- Better Communication and Collaboration Among Incident Response Teams: Clear protocols and communication channels enhance teamwork and coordination during incident response.
- Improved Customer Satisfaction and Trust: Efficient incident management demonstrates a commitment to security, fostering trust and confidence among customers.
Incident Response Strategies for Developers
Now that we understand the types of tools needed for effective incident response, let’s explore a proper incident response strategy that developers should follow.
Choosing the best incident management practices can significantly enhance your team’s ability to respond to incidents swiftly and effectively.
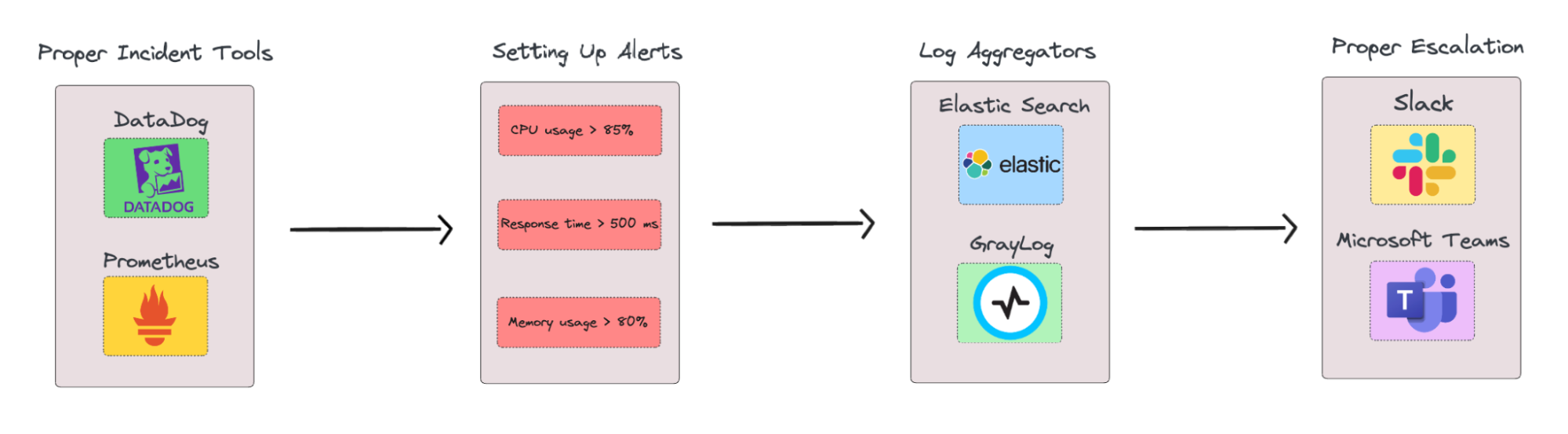
- Choose the Right Monitoring Tool: Start by selecting a reliable monitoring platform like Prometheus, Datadog, or New Relic. These tools offer real-time tracking of system metrics and performance, allowing developers to identify potential problems before they escalate.
- Set Up Alerts for Critical Metrics: Define critical metrics for your application or system, such as CPU usage, memory utilization, or response times. Set up alerts for thresholds that indicate abnormal behavior. For instance, if your CPU usage consistently stays above 85%, that could be an early sign of an upcoming failure.
- Use Log Aggregators for Better Visibility: Implement log aggregators like Elasticsearch, Graylog, or Splunk to collect, analyze, and correlate logs across systems. This provides better visibility into the system’s state and allows developers to identify anomalies quickly.
- Establish Clear Escalation Paths: Create a clear incident response protocol with defined escalation paths. When an alert is triggered, ensure that the right people are notified at the right time.
Implementing Incident Management
Implementing incident management involves several critical steps to ensure that incidents are handled effectively and efficiently. Here’s a roadmap to get you started:
- Develop an Incident Response Plan and Policy: Create a comprehensive incident response plan that outlines procedures for identifying, containing, eradicating, recovering from, and conducting post-incident activities.
- Establish an Incident Response Team and Define Roles and Responsibilities: Assemble a dedicated team with clearly defined roles to manage incidents. Ensure that each team member understands their responsibilities.
- Identify and Classify Incidents: Develop a system for identifying and classifying incidents based on their severity and impact. This helps prioritize response efforts.
- Contain and Eradicate Incidents: Implement measures to contain the incident and prevent further damage. Once contained, work on eradicating the root cause.
- Recover from Incidents and Restore Normal Operations: Focus on restoring affected systems and services to normal operations. Ensure that all data and systems are secure and functioning correctly.
- Conduct Post-Incident Activities: Perform a thorough post-incident analysis to understand what happened, why it happened, and how to prevent future incidents. Update your incident response plan based on the lessons learned.
Best Practices for Implementing Incident Management
To ensure the effectiveness of your incident management process, consider these best practices:
- Develop a Comprehensive Incident Response Plan: Include detailed procedures for each step of the incident response process, ensuring that all team members know what to do in various scenarios.
- Establish a Clear Incident Classification System: Prioritize incidents based on their severity and impact to ensure that the most critical issues are addressed first.
- Provide Regular Training and Exercises for Incident Response Teams: Conduct regular training sessions and simulation exercises to keep your team prepared and up-to-date with the latest incident response techniques.
- Conduct Regular Reviews and Updates of the Incident Response Plan: Periodically review and update your incident response plan to ensure it remains relevant and effective in addressing new and emerging threats.
- Implement Incident Management Software and Tools: Utilize incident management tools to streamline the incident response process, automate tasks, and improve overall efficiency.
- Establish a Culture of Incident Management: Foster an organizational culture where incidents are reported and addressed promptly. Encourage open communication and continuous improvement in incident management practices.
By following these best practices, organizations can enhance their incident management capabilities, ensuring a swift and effective response to security incidents.
Documatic’s Role in Effective Incident Management
Why Documatic?
When it comes to automating and managing incidents efficiently, Documatic stands out as a robust solution. It simplifies incident management by automating critical processes, helping developers track, identify, and resolve issues faster. With tools for centralizing communication and monitoring, Documatic enables teams to respond to incidents in real-time, reducing downtime and minimizing disruption.
Documatic’s platform integrates seamlessly with existing systems, offering issue root cause analysis, automated bridge call organization, and dependency mapping across multiple codebases. These features help teams efficiently pinpoint the source of incidents and coordinate response efforts. By reducing the need for manual investigation, developers can focus on resolving high-priority tasks rather than spending time on repetitive workflows.
How Documatic Aligns with Key Strategies
- Proactive Monitoring and Response
Documatic supports proactive incident response through issue root cause analysis, providing a detailed timeline of changes that may have triggered an error. This enables developers to quickly pinpoint the cause of incidents. Its dependency mapping across multiple codebases offers a clear visualization of connections between microservices, monorepos, and multiple databases, helping teams understand how issues spread across the infrastructure and codebases. - Cross-Functional Collaboration
Documatic improves cross-team collaboration by facilitating bridge call organization. When an incident is triggered, Documatic ensures that the right teams and engineers are involved by organizing bridge calls, allowing for faster and more efficient resolution. This helps ensure seamless communication among teams, minimizing response delays. - Streamlined Incident Identification
Documatic’s similar issue identification feature reduces noise in incident management tools by identifying related issues that occur across multiple codebases and services. This feature ensures that teams are not overwhelmed by duplicate alerts, enabling them to focus on addressing the root cause of incidents.
Need help managing incidents effectively and quickly? Start your free trial with Documatic today, and see how our platform can streamline your incident management, reduce manual effort, and improve response times. 🚀
Key Takeaways
In this article, we explored the essential strategies for effective incident management, from proactive monitoring to cross-functional collaboration and post-incident analysis. The key takeaway is that incident management isn’t just about responding to issues as they happen—it's about being prepared with the right tools and processes to minimize downtime, reduce overhead, and continuously improve your system’s reliability.
Preparation is key. By leveraging automation, AI, incident management tools, and integrated communication tools, teams can ensure that incidents are resolved swiftly, with minimal impact on business operations. This approach not only saves time and resources but also improves overall system performance.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments